SudoHack update & Replay system
So I really have to write another blog post. 120 of the 173 total commits for my Git repository have been after the last blog post and I start to feel bad about putting anything new in the game, because I should have documented all the other stuff already.
SudoHack update
Notably I started putting my Changelog online, drastically changed the game once, should have posted about it and changed it again. I am currently in the process of changing it another time. The first drastic change was losing your Bits a lot faster over time and gaining a lot more for every enemy kill. This essentially meant that you could not stand still or not kill enemies without dying, which was a lot closer to my creative vision I had from the start. I started feeling rather confident with the game and received good feedback, but I realized: to make a full fledged game out of it that offers the scope that I had in mind, I had to make a lot more levels. Taking in to account that the player only sees a subset of all the possible levels in every run, I estimated I had to make about 300 maps. In conjunction with the fact that it took me a least a week to make 6 I kind of liked, I had to take a different approach if I ever want to finish it (which is one of the main goals of this project), prompting the second radical change. So I revisited the two level generators I already started working on and dismissed pretty fast. And like always you just have to throw enough sweat and man hours at something to make something work and I arrived at something I rather like at the moment.
Screenshots:
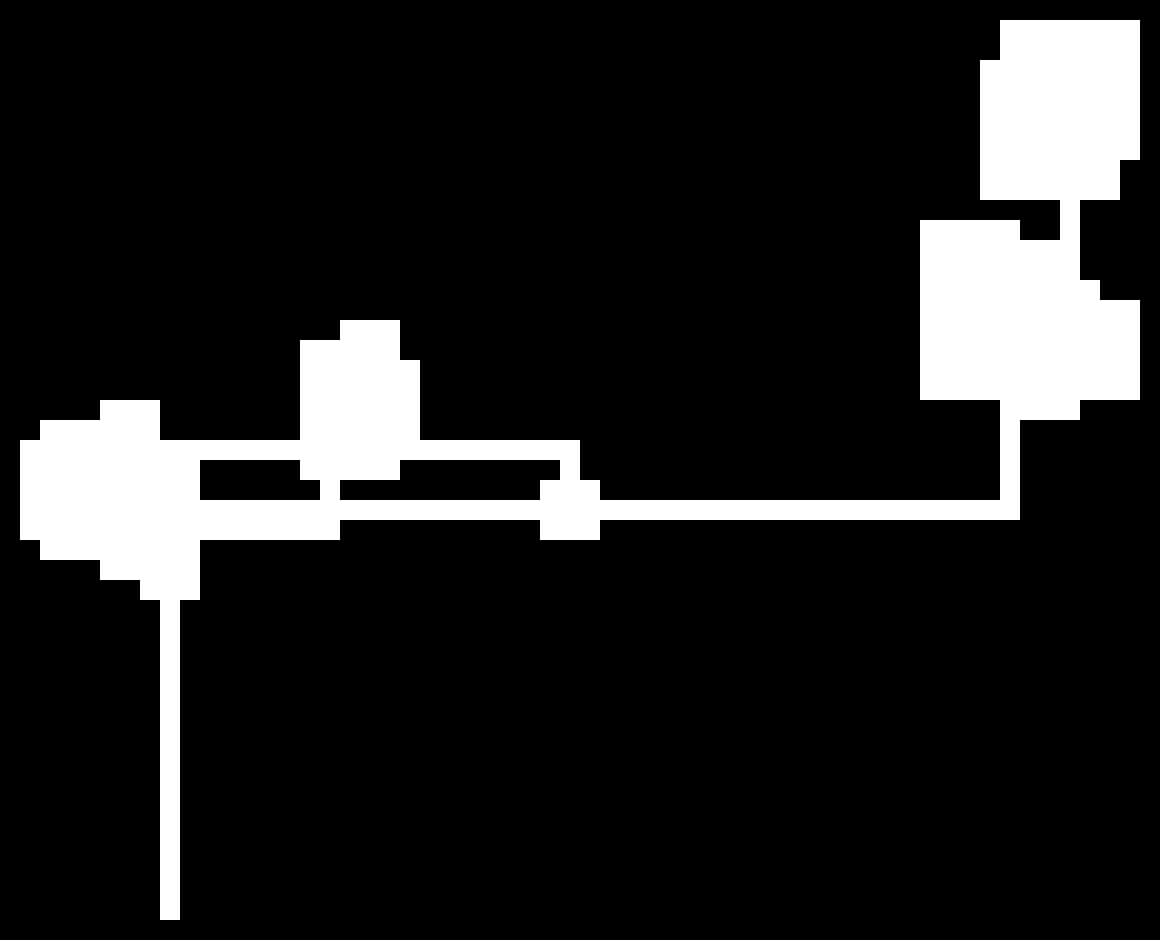
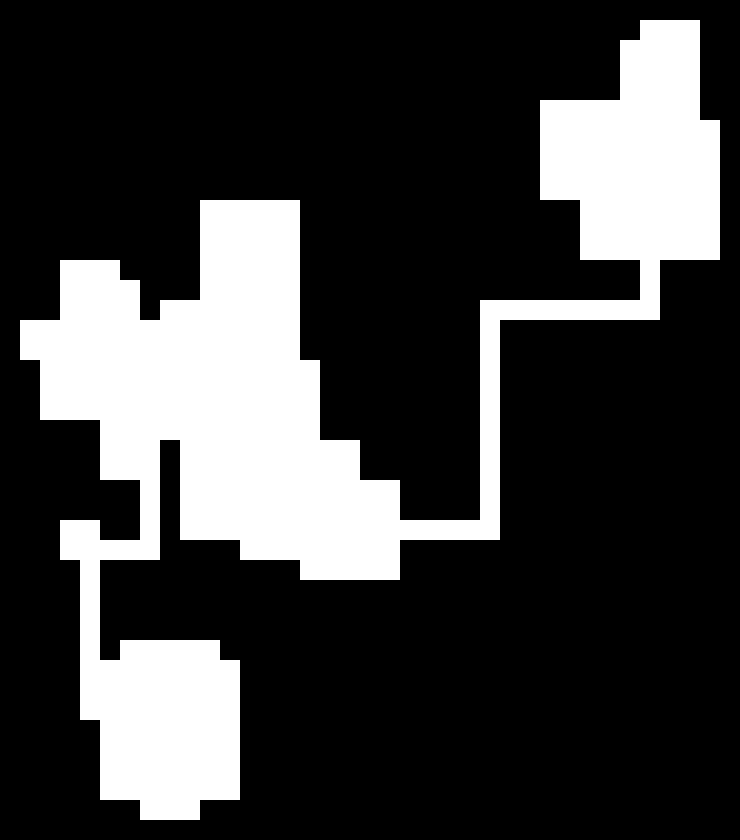
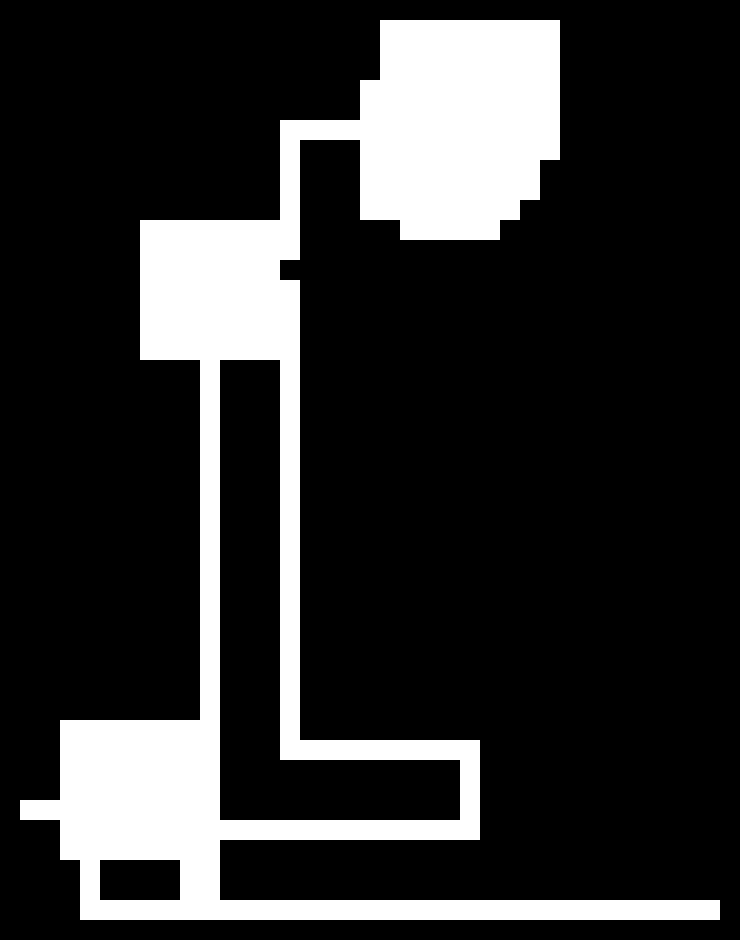
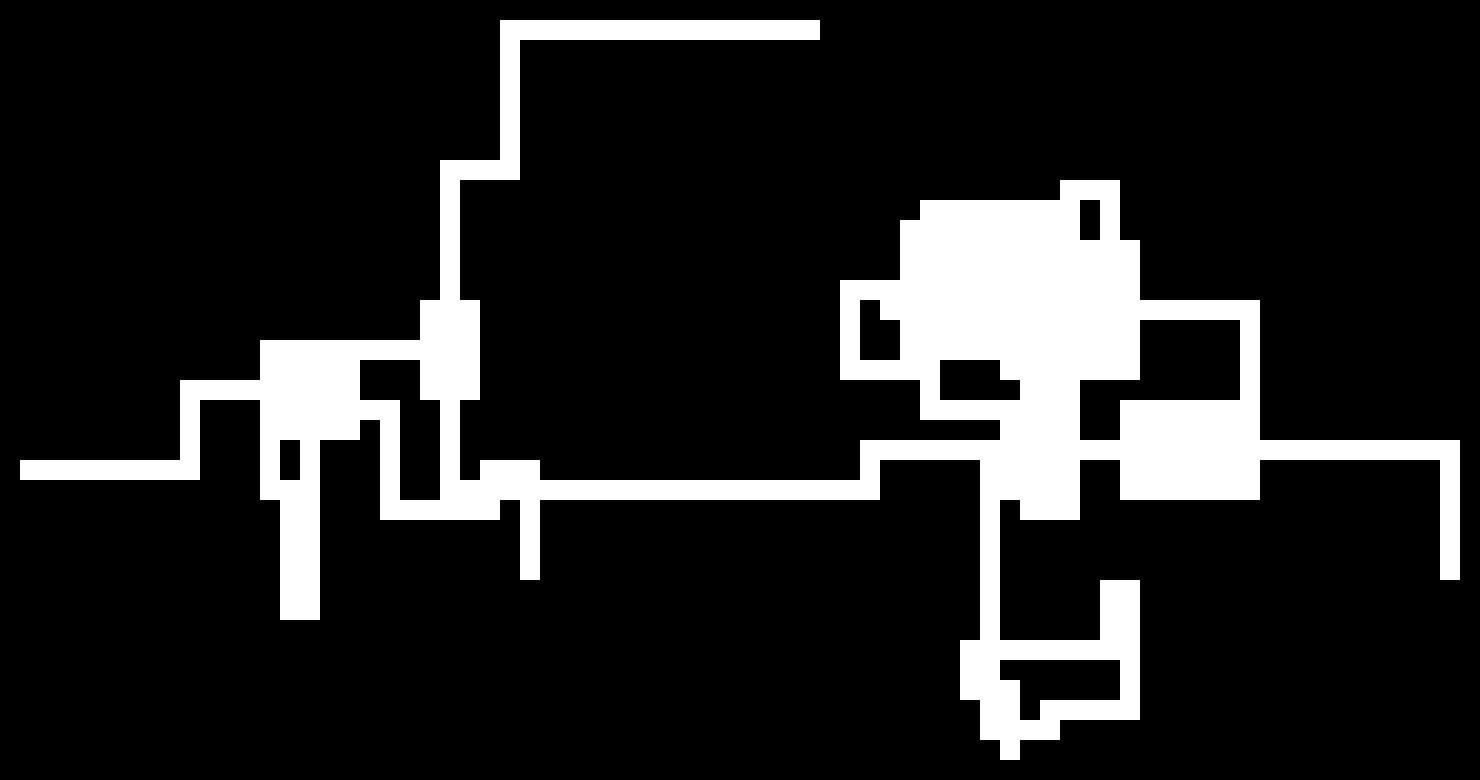
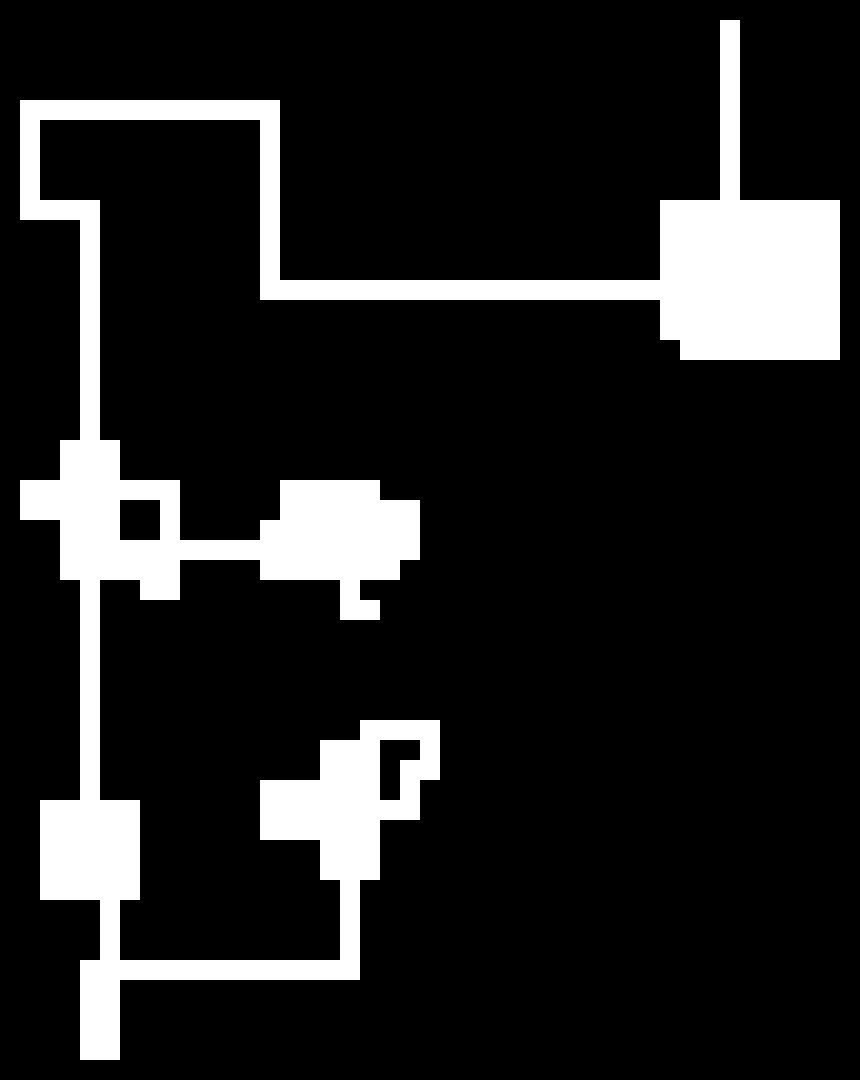
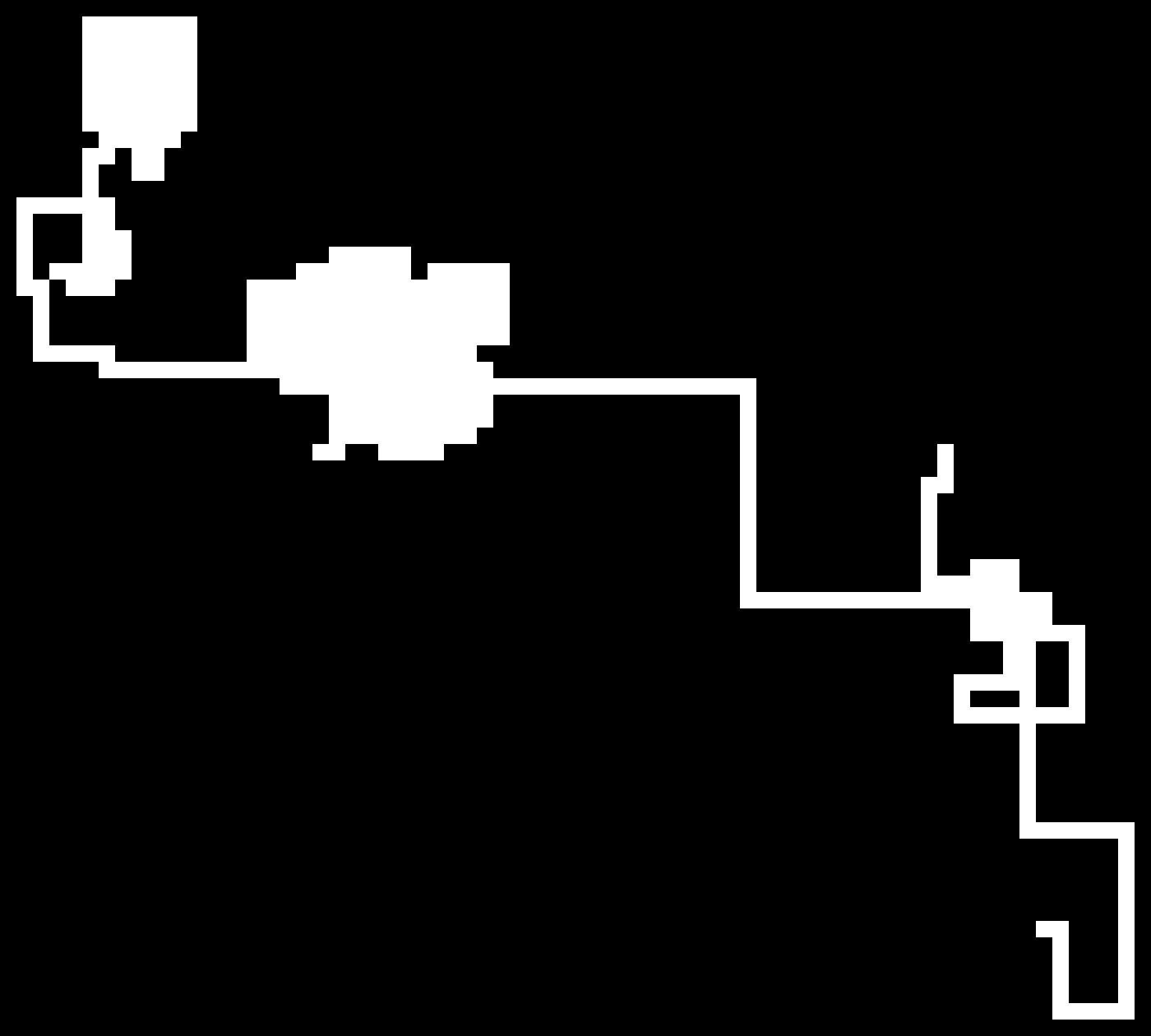




The algorithm is essentially a random walk in 2D (a little more fancy than that, but not too fancy) and as you can see in the limit of many steps we can observe a gaussian distribution (as expected with a random walk)! I just put them in to show that this algorithm works rather nicely for small maps (they are very similar to the ones I have built myself) and also quite okay for the medium sized ones.
With being able to have maps that are a little bigger than the ones before, I could, of course, not resist and also changed the scale of the maps a little. Sadly though I fairly quicky lost the stupid grin I acquired after implementing feature after feature and seeing the simulation time per frame steadily sticking at about 1ms. Apparently things aren’t always O(1) and sometimes even worse than O(n). But that’s why I kept a tidy list of any optimizations I could do if need ever be in my Trello, which I honestly couldn’t even wait to tackle.
A lot of the collision was optimized by only checking collision with the level geometry for the tile the object is currently on and surrounding tiles, but player-enemy and enemy-enemy collision never had a broadphase detection step, which I then implemented. After considering numerous approaches and comparing the necessary gain with the amount of work required I settled with the easiest solution, which is a grid/spatial hash. The whole grid effect was re-tweaked and optimized for only being applied to a little more than the visible tiles. Also other parts of the collision detection were optimized a little, I replaced a lot of if shape.type == “whatever” with table lookups, which proved to be exceptionally better. But I don’t even know why I didn’t do it from the start, since the code also got a lot smaller and prettier by doing it. It seems like I reached the point where I grew out of the code I wrote during the beginning of the project, meaning that I know more about the language now and get shivers running down my spine reading the early stuff. Also I implemented collision detection filtering for “idle” objects and enemy AI is now divided between “thinking” and “acting”. The former here represents the current state (and substate) of the enemy and it’s transitions between them, usually involving the more costly computations (ray casts, a lot of distance calculations) and the latter the behaviour, mostly consisting of accelerating towards something or shooting players (outrageous!).
Replay system
Something I spent a lot more time on than I should have is definitely gameplay recordings. I can’t spend a 40 hour week (or more) on this game and I certainly don’t have huge testing capacities, so I wanted to maximize the information I could get from the few testers I have.
As far as I see it, there are two fundamental approaches to doing this:
- recording user input and just "playing it back" afterwards
- recording snapshots of the whole game state and relevant events
As far as my analysis went the pros for each method are as follows:
- State snapshots
- will work even if you're simulation isn't deterministic, therefore less error prone considering differing floating point behaviour for different architectures (and potentially different binaries). But most networked games already have this requirement and deterministic simulations can be achieved without bending over backwards.
- probably smaller if the dimension of your state space is rather small (few enemies, bullets, etc.)
- Also you can choose arbitrary precision for most of your recorded data. It is not important that the player looks exactly in the direction it did while recording if it looks good enough, while it can be dangerous to truncate precision with keypress recording.
- a lot less dependent on mini-tweaks. Changing a value a little in enemy behaviour might lead to digressions that eventually destroy the recording
- you can record only a few seconds in the middle of the game without knowing the full history. This could also be done with keypress-recording but you would have to make a full state snapshot at the start, which is almost half the work of doing it completely with state snapshots.
- Rewinding and seeking are relatively easy to implement. Using keystrokes this is only possible with making snapshots every N frames and skipping to them.
- Keypresses
- probably smaller if the dimension of your state space is rather high (only a few inputs for potentially thousands of enemies/bullets)
- could potentially be coded once and reused for multiple projects (modulo extra meta data), given your simulations are always deterministic
- can be 'stapled on' later rather easily (again, determinism provided)
- could be used as a tool to reproduce bugs that are often difficult to produce
- the user can be recorded in the menu or during the pause screen and observing unwanted keypresses (the user trying out different keys because she/he doesn't know how something is supposed to work) or just how well the user can navigate those menus is essentially for free (but also mandatory). In essence: unwanted behaviour or behaviour not specifically expected might be observed, which is a useful tool for debugging.
- Gives you another reason to use a fixed timestep, which you definitely should (for framerate independent behaviour/making sure that approximation in the integrator is valid for the used dt, because physics might get weird with too small or too big dt/because it's crucial for networked multiplayer), though in-between frame interpolation might be needed.
In this case I thought that for my purpose, which is not actual ingame replay of something that is visible to the player but rather a being tool for me, the Keypress recording should be my method of choice. My implementation is Open Source an can be found here:
loveDemoLib (see main.lua for a usage example)
My googling showed (I could have made a histogram or something and tested it myself) that regular gamepads mostly have a precision of 10-12 Bit for every axis, so I tried using fixed precision for these floats by writing floor(val*GAMEPAD_AXIS_FP_PREC) and reading val/GAMEPAD_AXIS_FP_PREC. Apparently GAMEPAD_AXIS_FP_PREC being 10^5 - 1 or 10^6 - 1 is still enough to throw the simulation off rather quickly. I assume this is because of binning problems e.g. non-homogeneous density of float numbers in the interval -1 to 1 in contrast to homogeneous density of fixed point numbers in this interval, so that some fixed point numbers correspond to multiple floats and some to none.
Also I really wanted to implement binary writing, but it is far too much of a hassle in Lua if you want to write numbers (extracting every byte yourself for integers and mantissa/exponent for floats). It’s certainly not inconceivably hard, but considering that I wrote the uploader in Python, zipping the file before uploading guarantees that the file to upload is seldom bigger than 1MB, which is in this day and age totally acceptable, I think.
Integration
First I added a pre-commit to my git repository that calls a Python script which then replaced certain variables in my code. For now it’s just a timestamp of the commit (I would really like to have a hash, but I can’t get the hash of the commit before commiting of course and later commiting the changed file is also suboptimal) so I can (almost) uniquely identify different versions of the game and can always checkout the necessary version to play back a specific recording.
Then I added an awesome duo of an uploader, written in Python:
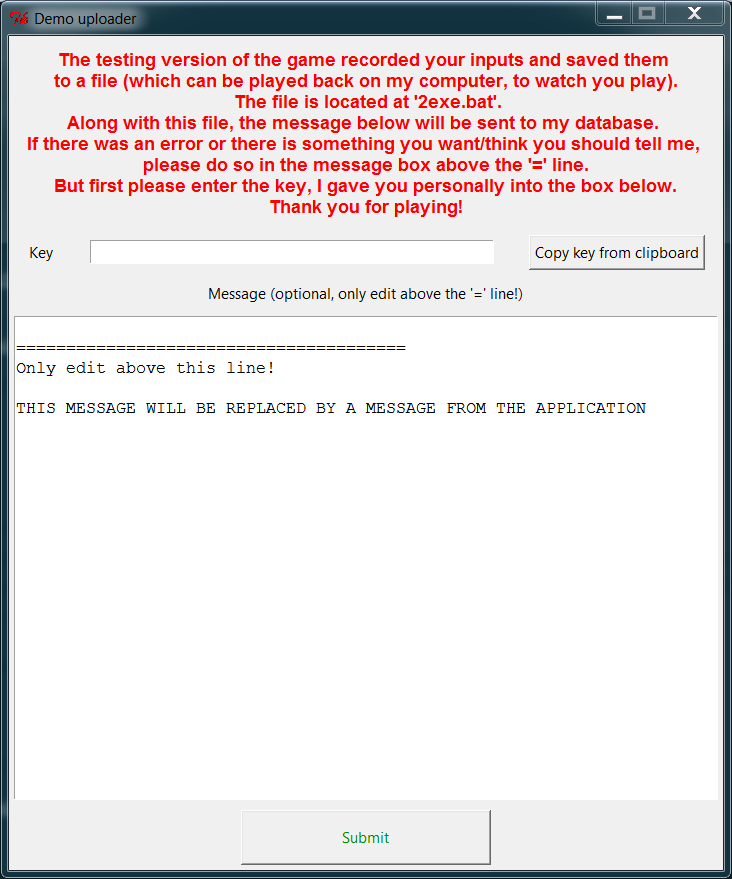
and a Web interface for adding keys and overviewing and downloading the recordings uploaded by the testers (also I love Bootstrap):
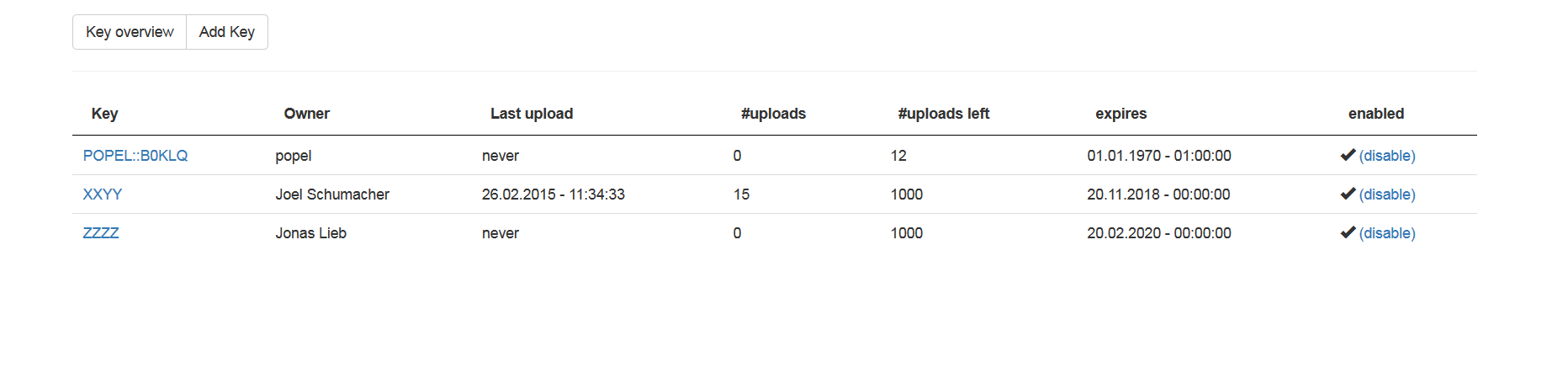

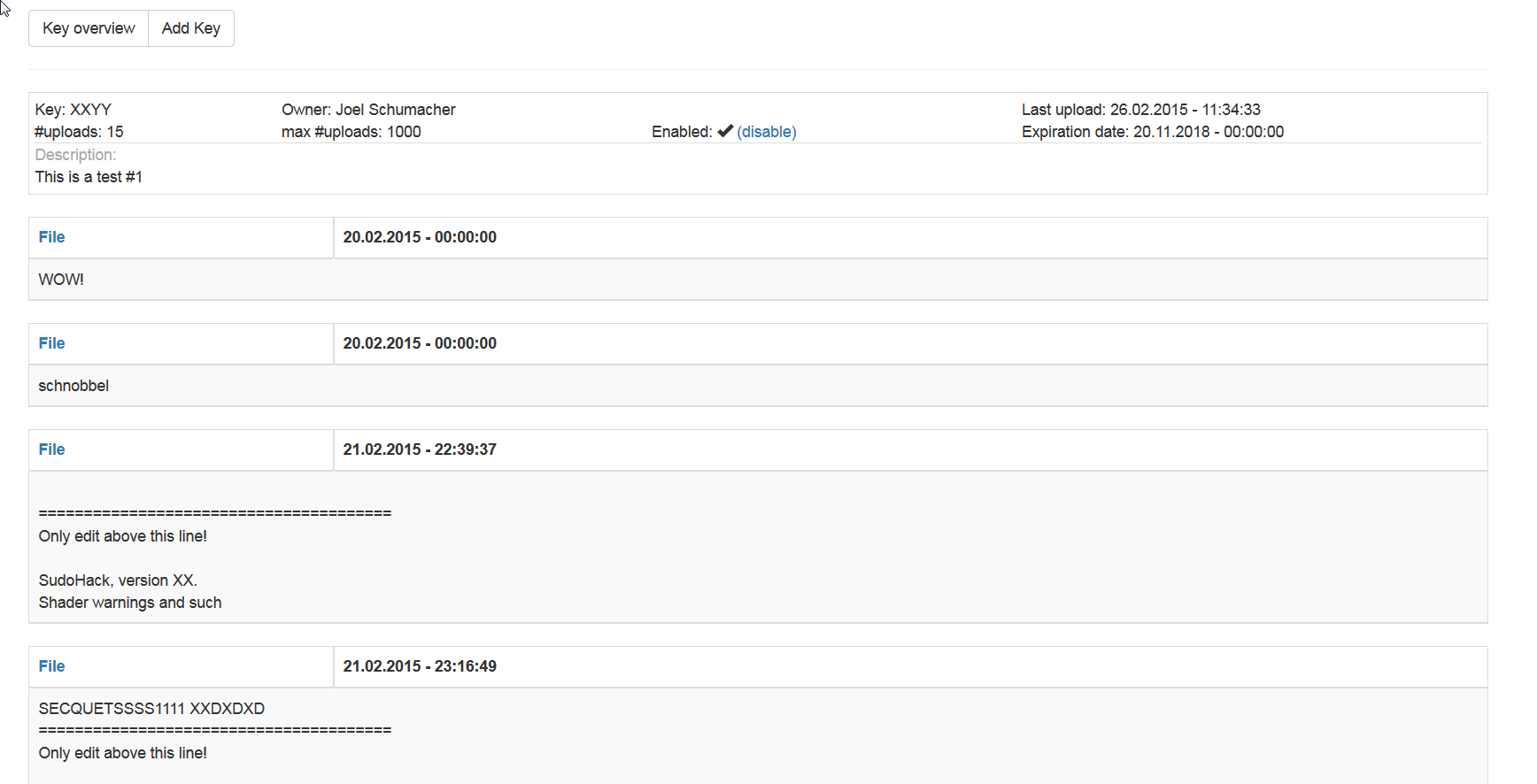
They are far from great and there is a lot of stuff I would change if I could justify putting any more work into them, but the only people that will ever use them are probably people I personally know quite well, so I don’t feel super bad about it.
Of course I also did a bit of other stuff in 120 commits, but I want to write them up in a later blog post with a little more context (and screenshots and videos of course).